
Introduction
Can you trust a single model to give you the right result? Like studying and research, multiple sources are necessary to corroborate a claim or statement. That statement is true for data aswell. With more and more data being analyzed, you have to check . Ensemble learning has a similar approach to double, triple, and quadruple checking; it combines multiple models to achieve better predictions than any single model could provide alone, becoming a cornerstone of modern machine learning applications.
From financial forecasting to medical diagnosis, ensemble methods have demonstrated their effectiveness across diverse domains. These techniques not only enhance prediction accuracy but also provide more robust and reliable results, making them invaluable tools in the machine learning toolkit.
Why Use Ensemble Learning?
Machine learning models struggle with either high variance or high bias or overfitting and underfitting. High variance models fit training data too closely (overfitting) and fail to generalize. High bias models are too simplistic (underfitting) and don’t accurately represent the data. Ensemble learning addresses bias and variance by aggregating multiple models’ evaluations to come to a more comprehensive conclusion
When multiple models are aggregated, via averaging, voting, or weighted, the ensemble is often more accurate and stable than any single model. Different models may make different errors, and combining them can cancel out individual faults.
Ensemble learning is especially useful in the following scenarios:
- Unstable models: Decision Trees can be sensitive to small changes in data. Bagging methods like Random Forests stabilize predictions.
- Complex patterns: No single model captures all relationships in high-dimensional or nonlinear data. Ensembles can model a wider range of patterns.
- Noisy data: By pooling outputs, ensembles can reduce the impact of noise.
While ensemble methods often sacrifice some interpretability and increase computational cost, their performance benefits make them a preferred choice for production-level systems and high-stakes predictive tasks.
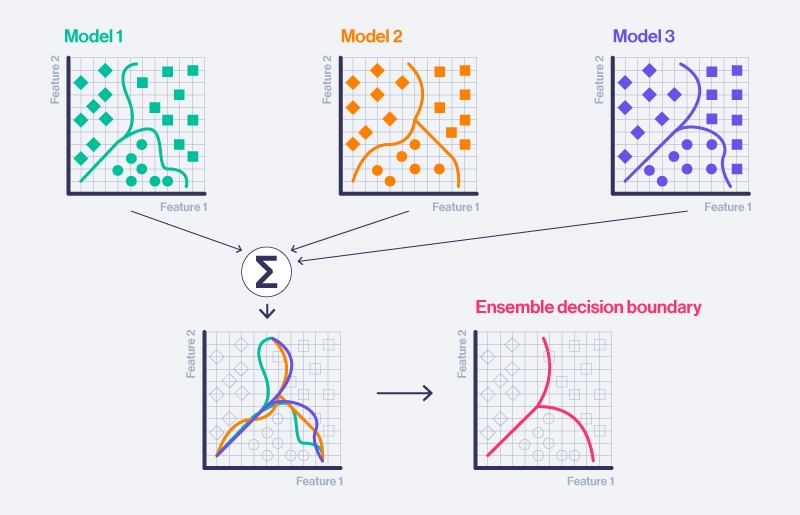
Types of Ensemble Learning Techniques
Bagging (Bootstrap Aggregating)
In bagging, each model is trained independently on a different random subset of the training data. Their predictions are aggregated, typically through majority voting for classification or averaging for regression. This reduces model variance and improves stability.
Bagging trains multiple instances of the same base model on different subsets of the training data. Each subset is drawn randomly with replacement. Final predictions are made by averaging (regression) or majority voting (classification).
- Goal: Reduce variance and overfitting
- Common base models: Decision Trees
- Example algorithms:
- Random Forest
- Bagged Decision Trees
Boosting
In boosting, models are trained sequentially. Each new model focuses on the mistakes of the previous one, with examples weighted according to past errors. Final predictions are a weighted sum of the individual models. This process reduces bias and builds a strong learner from weak ones.
Boosting builds models sequentially, with each new model trained to correct the errors of the previous one. Predictions are combined using weighted averages or sums, giving more influence to models that perform better.
- Goal: Reduce bias and improve predictive accuracy
- Common base models: Shallow Decision Trees (Stumps)
- Example algorithms:
- AdaBoost
- Gradient Boosting Machines (GBM)
- XGBoost
- LightGBM
- CatBoost
Stacking (Stacked Generalization)
In stacking, multiple diverse models are trained in parallel. Their outputs are used as input features for a higher-level model (the meta-learner), which learns how to best combine them. This approach captures patterns that individual models may miss.
Stacking combines different types of models by training a separate model, called a meta-learner, to learn how to best blend their outputs. Base models are trained in parallel, and their predictions are used as input features for the meta-learner.
- Goal: Leverage model diversity for improved performance
- Common base models: Any mix (e.g., SVMs, Trees, Neural Networks)
- Example algorithms:
- StackingClassifier (available in scikit-learn)
- Custom stacking pipelines